你有没有想过,当我们在观看视频或者听音乐的时候,是不是可以只提取出人声部分呢?这听起来是不是很神奇?没错,今天就要来聊聊这个让人眼前一亮的技术——人声提取。想象你可以在嘈杂的背景音乐中,轻松地听到歌手的歌声,或者在电影中,只保留对话部分,是不是很酷呢?
人声提取,顾名思义,就是从音频信号中提取出人声的过程。这项技术利用了音频处理和信号处理的知识,通过算法分析,将人声从其他声音中分离出来。听起来是不是很复杂?其实,随着科技的发展,这项技术已经越来越成熟,甚至可以在手机上轻松实现。
人声提取的应用场景非常广泛,以下是一些典型的例子:
1. 音乐制作:音乐制作人可以利用人声提取技术,将歌手的歌声从伴奏中分离出来,进行后期混音和编辑。
2. 语音识别:在语音识别领域,人声提取技术可以帮助设备更准确地识别用户的语音指令。
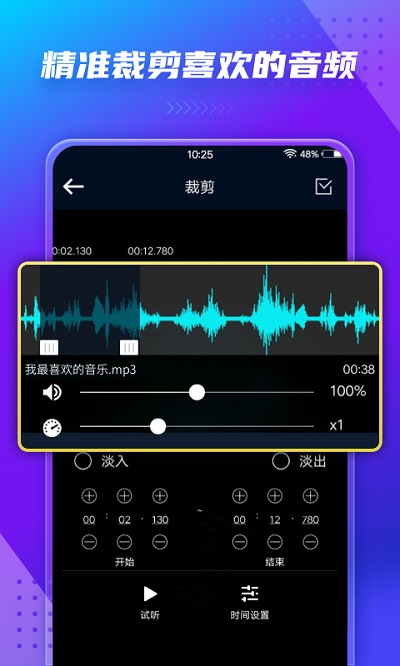
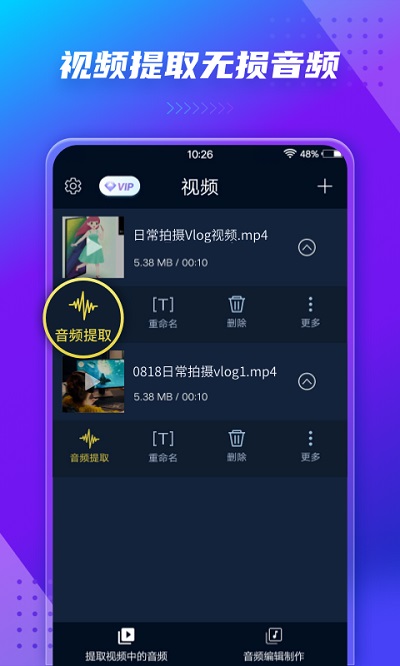
3. 视频剪辑:在视频剪辑过程中,人声提取可以让我们只保留对话部分,或者去除不需要的背景噪音。
4. 教育领域:在教育领域,人声提取技术可以帮助学生更好地学习语言,通过提取出人声,学生可以更专注于听力和口语练习。
人声提取技术主要基于以下几个原理:
1. 频谱分析:通过分析音频信号的频谱,找出人声特有的频率范围。
2. 短时傅里叶变换(STFT):将音频信号分解成短时片段,然后对每个片段进行傅里叶变换,从而得到频谱信息。
3. 谱减法:通过对比人声和非人声的频谱,找出人声特有的频段,然后对人声频段进行增强,非人声频段进行抑制。
4. 深度学习:近年来,深度学习技术在人声提取领域取得了显著成果。通过训练神经网络模型,可以实现对音频信号的高效提取。
尽管人声提取技术已经取得了很大进步,但仍然面临一些挑战:
1. 噪声干扰:在嘈杂的环境中,人声提取技术可能会受到噪声干扰,导致提取效果不佳。
2. 多声道问题:在多声道音频中,人声提取技术需要同时处理多个声道,增加了算法的复杂性。
3. 人声识别:在提取人声的同时,还需要识别出说话者的身份,这对于算法提出了更高的要求。
随着人工智能和深度学习技术的不断发展,人声提取技术将会越来越成熟。未来,我们可以期待以下发展趋势:
1. 实时人声提取:在实时场景中,人声提取技术可以实现实时处理,为用户带来更加便捷的体验。
2. 个性化人声提取:根据用户的需求,实现个性化的人声提取效果。
3. 跨语言人声提取:随着全球化的推进,跨语言的人声提取技术将成为可能。
人声提取技术已经成为了音频处理领域的一颗璀璨明珠。相信在不久的将来,这项技术将会为我们的生活带来更多惊喜。